昨年末に, こちら[1] のページで, YOLOv3アルゴリズムをTensorFlow 2.0で実行できるように対応したバージョンがあることを知りました.
(TensorfFlow 1.xで動作するものがあることは知ってましたが....)

現在, ピープルカウンタの開発[2][3]でYOLOv3[4]を利用しているので興味がわき, 少し試してみることにした.
基本的には, こちら[5]のGithubのページのリポジトリをダウンロードし, 動作させると問題なく動きます.
ただ, グレースケール画像を扱ったり, モデルの入力画像サイズを変更したりする場合, 正常に動作しなかったので, メモとしてまとめておく.
1. 基本的な動作
Githubの説明のとおりやれば, 問題なく動作しました.
1.1 学習済YOLOv3モデルの変換
# yolov3 wget https://pjreddie.com/media/files/yolov3.weights -O data/yolov3.weights python convert.py # yolov3-tiny wget https://pjreddie.com/media/files/yolov3-tiny.weights -O data/yolov3-tiny.weights python convert.py --weights ./data/yolov3-tiny.weights --output ./checkpoints/yolov3-tiny.tf --tiny
1.2 物体検知
# yolov3 python detect.py --image ./data/meme.jpg # yolov3-tiny python detect.py --weights ./checkpoints/yolov3-tiny.tf --tiny --image ./data/street.jpg # webcam python detect_video.py --video 0 # video file python detect_video.py --video path_to_file.mp4 --weights ./checkpoints/yolov3-tiny.tf --tiny # video file with output python detect_video.py --video path_to_file.mp4 --output ./output.avi
2. グレースケール画像対応
ピープルカウンタの開発で学習したモデル(224x224x1)をconvert.pyで変換しようとすると, 以下のようなエラーが発生する.
:
WARNING:tensorflow:Model was constructed with shape Tensor("input_2:0", shape=(None, None, None, 3), dtype=float32) for input (None, None, None, 3), but it was re-called on a Tensor with incompatible shape (None, None, None, 1).
W0112 10:48:52.597801 140539316311872 network.py:847] Model was constructed with shape Tensor("input_2:0", shape=(None, None, None, 3), dtype=float32) for input (None, None, None, 3), but it was re-called on a Tensor with incompatible shape (None, None, None, 1).
Traceback (most recent call last):
File "convert.py", line 39, in <module>
app.run(main)
File "/home/aska/anaconda3/envs/yolov3-tf2-gpu/lib/python3.7/site-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/home/aska/anaconda3/envs/yolov3-tf2-gpu/lib/python3.7/site-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
:
File "/home/aska/anaconda3/envs/yolov3-tf2-gpu/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/input_spec.py", line 213, in assert_input_compatibility
' but received input with shape ' + str(shape))
ValueError: Input 0 of layer conv2d is incompatible with the layer: expected axis -1 of input shape to have value 3 but received input with shape [None, None, None, 1]原因を調べた結果, yolov3-tf2/models.pyで, channels=3固定でコーディングしてる箇所があり, そこを指定できるように変更することで問題なく変換できることを確認した.
[修正前]
def Darknet(name=None): x = inputs = Input([None, None, 3]) x = DarknetConv(x, 32, 3) x = DarknetBlock(x, 64, 1) : def DarknetTiny(name=None): x = inputs = Input([None, None, 3]) x = DarknetConv(x, 16, 3) x = MaxPool2D(2, 2, 'same')(x) x = DarknetConv(x, 32, 3) :
[修正後]
def Darknet(name=None, channels=3): x = inputs = Input([None, None, channels]) x = DarknetConv(x, 32, 3) x = DarknetBlock(x, 64, 1) : def DarknetTiny(name=None, channels=3): x = inputs = Input([None, None, channels]) x = DarknetConv(x, 16, 3) x = MaxPool2D(2, 2, 'same')(x) x = DarknetConv(x, 32, 3) :
グレースケール画像を扱うときは, convert.pyやdetect.py等からDarkent/DarknetTinyを呼び出すときに引数でchannels=1を指定すること.
3. モデルの入力画像サイズ対応
ピープルカウンタをJetson Nanoで動かすために, モデルの入力画像サイズを416から224に変更してモデルを学習しているのだが, 実行すると人物検出領域のボックス位置がおかしい.

こちらも, 原因を調べてみると, yolov3-tf2/models.pyで, 入力画像サイズを416固定で処理している箇所が見つかった.
こちらは, とりあえず入力画像サイズを224に変更し, こちらが影響していることを確認した.
[変更前]
yolo_anchors = np.array([(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373, 326)], np.float32) / 416 yolo_anchor_masks = np.array([[6, 7, 8], [3, 4, 5], [0, 1, 2]]) yolo_tiny_anchors = np.array([(10, 14), (23, 27), (37, 58), (81, 82), (135, 169), (344, 319)], np.float32) / 416 yolo_tiny_anchor_masks = np.array([[3, 4, 5], [0, 1, 2]])
[変更後]
yolo_anchors = np.array([(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373, 326)], np.float32) / 224 yolo_anchor_masks = np.array([[6, 7, 8], [3, 4, 5], [0, 1, 2]]) yolo_tiny_anchors = np.array([(10, 14), (23, 27), (37, 58), (81, 82), (135, 169), (344, 319)], np.float32) / 224 yolo_tiny_anchor_masks = np.array([[3, 4, 5], [0, 1, 2]])
コード変更後に確認すると, 一応問題は解決されたようだ!!.
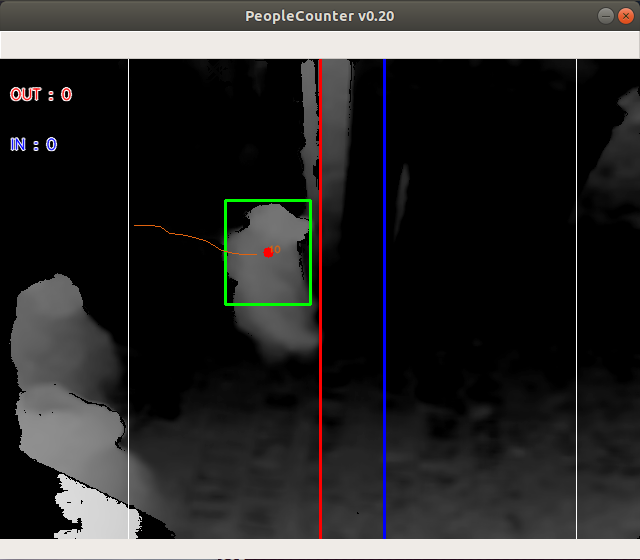
YOLOv3 + TensorFlow 2.0で, ピープルカウンタが一応動作するようになった. (Linux PC上だが...)
せっかく動作するところまで確認できたので, こんどJetson Nanoでどの程度の処理スピードなのか, 是非確認してみたい.
15FPS以上でると嬉しいのだが...
----
参照URL:
[1] Tensorflow 2.0を用いた物体検知
[2] ピープルカウンタを考えてみる(7)
[3] Jetson NanoでIntel RealSenseを試してみる(3)
[4] YOLO: Real-Time Object Detection
[5] YoloV3 Implemented in Tensorflow 2.0
") TensorFlowとKerasで動かしながら学ぶ ディープラーニングの仕組み ~畳み込みニューラルネットワーク徹底解説~ (Compass Booksシリーズ)
|
") 詳解ディープラーニング 第2版 ~TensorFlow/Keras・PyTorchによる時系列データ処理~ (Compass Booksシリーズ)
|
 TensorFlow&Kerasプログラミング実装ハンドブック
|
")