最近, YOLOv5, YOLOXやDetectron2などを少し触る機会があったので, まずはYOLOv5について少しまとめておく.
前回はYOLOv5インストールおよび推論編について記載したが, 今回は学習編ということで, オリジナルデータを使ったモデル学習について記す.
3. 学習[1]
3.1 アノテーション
オリジナルデータでモデル学習するためには, 学習データに対してこれは「XXX」, これは「YYY」などと, 検出する物体を囲む矩形(バウンディングボックス)の指定とラベルを付与する必要がある.
今回は, 以前開発したピープルカウンタ[2]のデータ(Intel Depth Sensorの距離画像を処理したもの)を用いる.
[画像]

上記画像に対し, 以下のようなYOLO形式のラベルファイルを作成する.
フォーマット:
クラス番号 物体重心位置[x, y] サイズ[w, h]
0 0.7469163501410836 0.22516973601567405 0.1852987834331521 0.2610307903593224 0 0.42223105003787753 0.647709003215434 0.23650070079951857 0.37299035369774913
注) 位置, サイズは, 画像サイズに対する比率で表現
この作業にはオーサリングツールを用いる.
無料のツールもいくつかあるので, ラベルの出力フォーマットや使いやすさなどから選べばよい.
以前はVoTT[3]を使用していたが, 最近はYOLO形式で出力できるIabelImg[4]を使用することも増えてきた.
データとラベルは, 以下のディレクトリに配置する.
data ─── train_data ─── images/
└── labels/
└── val_data ─── images/
└── labels/
3.2 学習
今回, 学習済みのyolov5s.ptをもとに, オリジナルデータとそのラベルファイルを使って再学習を行う.
学習手順
(1) 学習済みモデル(yolov5s.pt)をダウロードし, modelsの下に配置する.
学習済みモデルは, 下記のサイトからダウンロードすることができる.
github.com
(2) data/coco.yamlをベースに, configファイル(今回はhug2.yaml)を作成する.
configファイル内の学習/評価データのディレクトリ, クラス数, クラス名を設定する.
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) train: data/train_data/images val: data/val_data/images # Classes nc: 1 # number of classes names: ['passer'] # class names
(3) モデルを学習する.
$ python train.py --data data/hug2.yaml --cfg models/yolov5s.yaml --weights models/yolov5s.pt --img 640 --batch-size 32 --epochs 100
train: weights=models/yolov5s.pt, cfg=models/yolov5s.yaml, data=data/hug2.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=100, batch_size=32, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
From https://github.com/ultralytics/yolov5
e54e758..cee5959 master -> origin/master
* [new branch] apple/mps -> origin/apple/mps
8ddfd6a..152d964 classifier -> origin/classifier
* [new branch] test/FReLU_v2 -> origin/test/FReLU_v2
932f456..c58f17a test/conv_reduction -> origin/test/conv_reduction
* [new branch] test/convtranspose -> origin/test/convtranspose
* [new branch] test/dw5 -> origin/test/dw5
* [new branch] test/nature -> origin/test/nature
* [new branch] test/poly -> origin/test/poly
7ff7fc2..4d16efb test/python_versions -> origin/test/python_versions
* [new branch] ultralytics/HUB -> origin/ultralytics/HUB
* [new branch] v7.0 -> origin/v7.0
* [new branch] v7.0-dwconv2dtranspose -> origin/v7.0-dwconv2dtranspose
github: ⚠️ YOLOv5 is out of date by 50 commits. Use `git pull` or `git clone https://github.com/ultralytics/yolov5` to update.
YOLOv5 🚀 v6.1-161-ge54e758 torch 1.10.2+cu113 CUDA:0 (NVIDIA GeForce RTX 3060, 12054MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=1
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5s summary: 270 layers, 7022326 parameters, 7022326 gradients, 15.8 GFLOPs
Transferred 342/349 items from models/yolov5s.pt
Scaled weight_decay = 0.0005
optimizer: SGD with parameter groups 57 weight (no decay), 60 weight, 60 bias
albumentations: Blur(always_apply=False, p=0.01, blur_limit=(3, 7)), MedianBlur(always_apply=False, p=0.01, blur_limit=(3, 7)), ToGray(always_apply=False, p=0.01), CLAHE(always_apply=False, p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
train: Scanning '/home/aska/Project/Hug2/yolov5/data/train_data/labels.cache' images and labels... 2528 found, 0 missing, 0 empty, 0 corrupt: 100%|██████████| 2train: Scanning '/home/aska/Project/Hug2/yolov5/data/train_data/labels.cache' images and labels... 2528 found, 0 missing, 0 empty, 0 corrupt: 100%|██████████| 2528/2528 [00:00<?, ?it/s]
val: Scanning '/home/aska/Project/Hug2/yolov5/data/val_data/labels.cache' images and labels... 632 found, 0 missing, 0 empty, 0 corrupt: 100%|██████████| 632/63val: Scanning '/home/aska/Project/Hug2/yolov5/data/val_data/labels.cache' images and labels... 632 found, 0 missing, 0 empty, 0 corrupt: 100%|██████████| 632/632 [00:00<?, ?it/s]
Plotting labels to runs/train/exp2/labels.jpg...
AutoAnchor: 5.69 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs/train/exp2
Starting training for 100 epochs...
: (省略)
Epoch gpu_mem box obj cls labels img_size
97/99 8.11G 0.01325 0.007735 0 74 640: 100%|██████████| 79/79 [00:22<00:00, 3.55it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 10/10 [00:02<00:00, 4.04it/s]
all 632 887 0.983 0.988 0.993 0.772
Epoch gpu_mem box obj cls labels img_size
98/99 8.11G 0.01303 0.007623 0 92 640: 100%|██████████| 79/79 [00:22<00:00, 3.52it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 10/10 [00:02<00:00, 4.04it/s]
all 632 887 0.979 0.99 0.992 0.774
Epoch gpu_mem box obj cls labels img_size
99/99 8.11G 0.01303 0.007568 0 81 640: 100%|██████████| 79/79 [00:22<00:00, 3.54it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 10/10 [00:02<00:00, 4.05it/s]
all 632 887 0.977 0.991 0.993 0.777
100 epochs completed in 0.698 hours.
Optimizer stripped from runs/train/exp2/weights/last.pt, 14.4MB
Optimizer stripped from runs/train/exp2/weights/best.pt, 14.4MB
Validating runs/train/exp2/weights/best.pt...
Fusing layers...
YOLOv5s summary: 213 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 10/10 [00:04<00:00, 2.24it/s]
all 632 887 0.982 0.984 0.993 0.781
Results saved to runs/train/exp学習を実行すると, "runs/train/expXX"に学習に関連する情報や, "runs/train/expXX/weights"に学習済みモデルが保存される.
以下, 学習関連情報の一例.
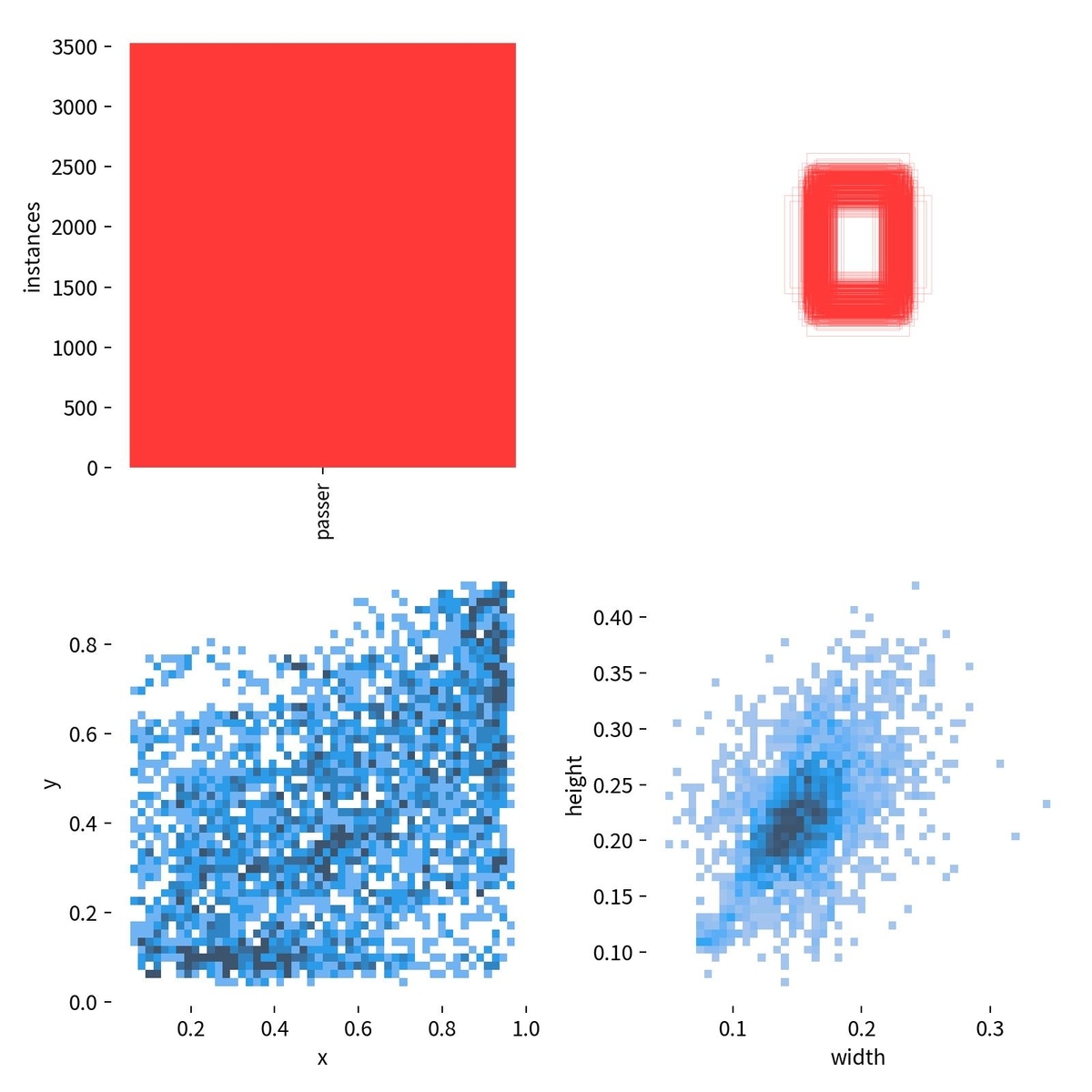
・labels.jpg
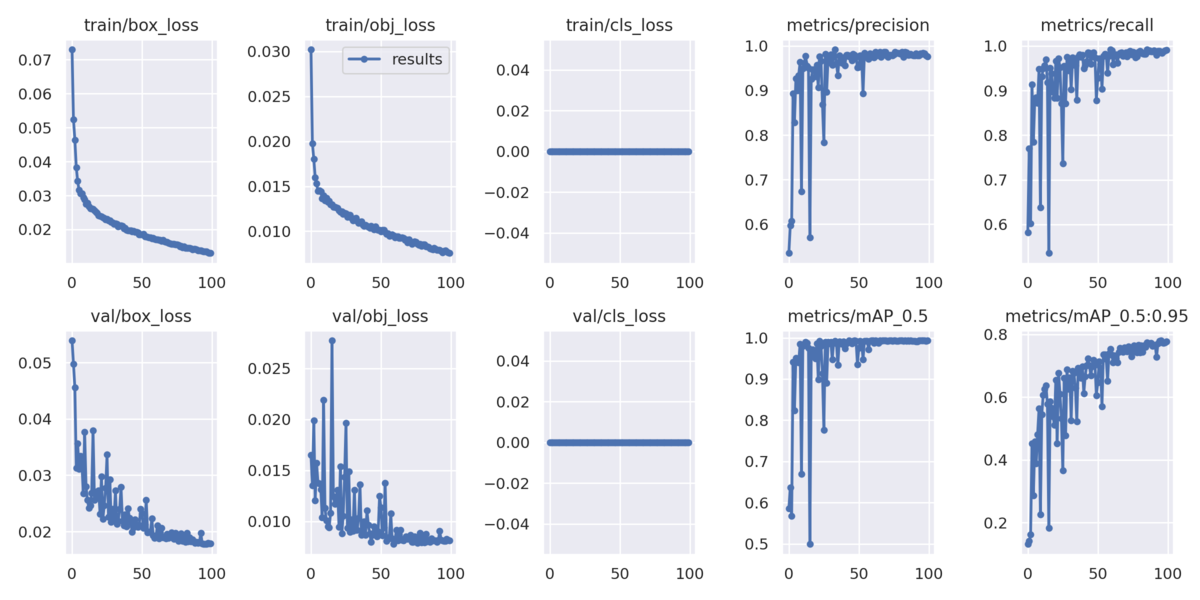
・results.png
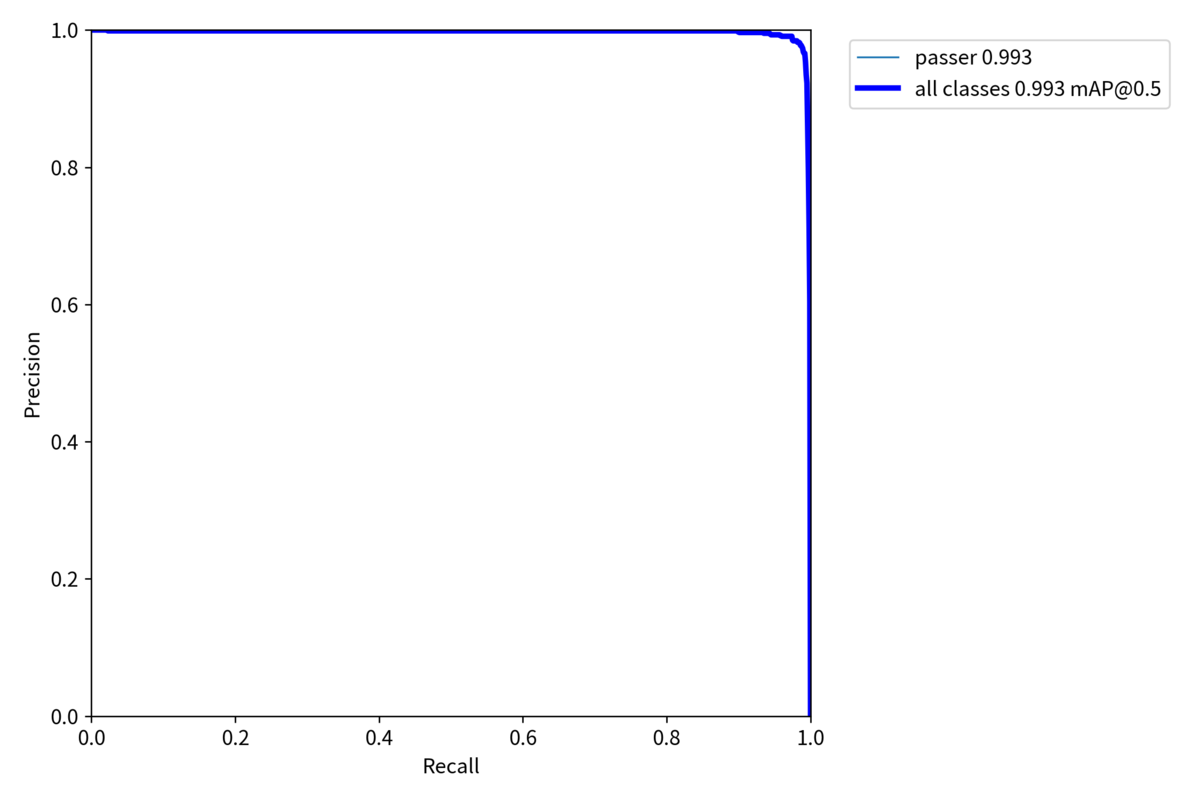
・PR_curve.png
・val_batch2_labels.jpg / val_batch2_pred.jpg


これら以外にも, 多数の情報が出力されている.
3.3 推論
学習が完了したら, そのモデルを使って推論を行ってみる.
$ python detect.py --source data/val_data/images/FCam9_00000158.jpg --weights runs/train/exp/weights/best.pt detect: weights=['runs/train/exp2/weights/best.pt'], source=data/val_data/images/FCam9_00000158.jpg, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 🚀 v6.1-161-ge54e758 torch 1.10.2+cu113 CUDA:0 (NVIDIA GeForce RTX 3060, 12054MiB) Fusing layers... YOLOv5s summary: 213 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs image 1/1 /data/Project/Hug2Data/labeled_data/AM9/labels/Hug2-gray-2018-PascalVOC-export/val_data/images/FCam9_00000158.jpg: 480x640 2 passers, Done. (0.013s) Speed: 0.3ms pre-process, 13.1ms inference, 0.9ms NMS per image at shape (1, 3, 640, 640) Results saved to runs/detect/exp
推論を実行すると, "runs/detect/expXX"に推論結果が画像として保存される.

yolov3のときの学習と比較すると, configファイルの設定などが簡単になっており, かなり使いやすい.
次回は, yolov5で学習したモデルを, onnxなど他のフレームワークのモデルに変換するあたりを紹介しようと思う.
----
[1] Train Custom Data - YOLOv5
[2] ピープルカウンタを考えてみる(7)
[3] GitHub - microsoft/VoTT
[4] GitHub - tzutalin/labelImg


")
